 Balance
Balancepython基础-进阶
5分钟了解系列-python
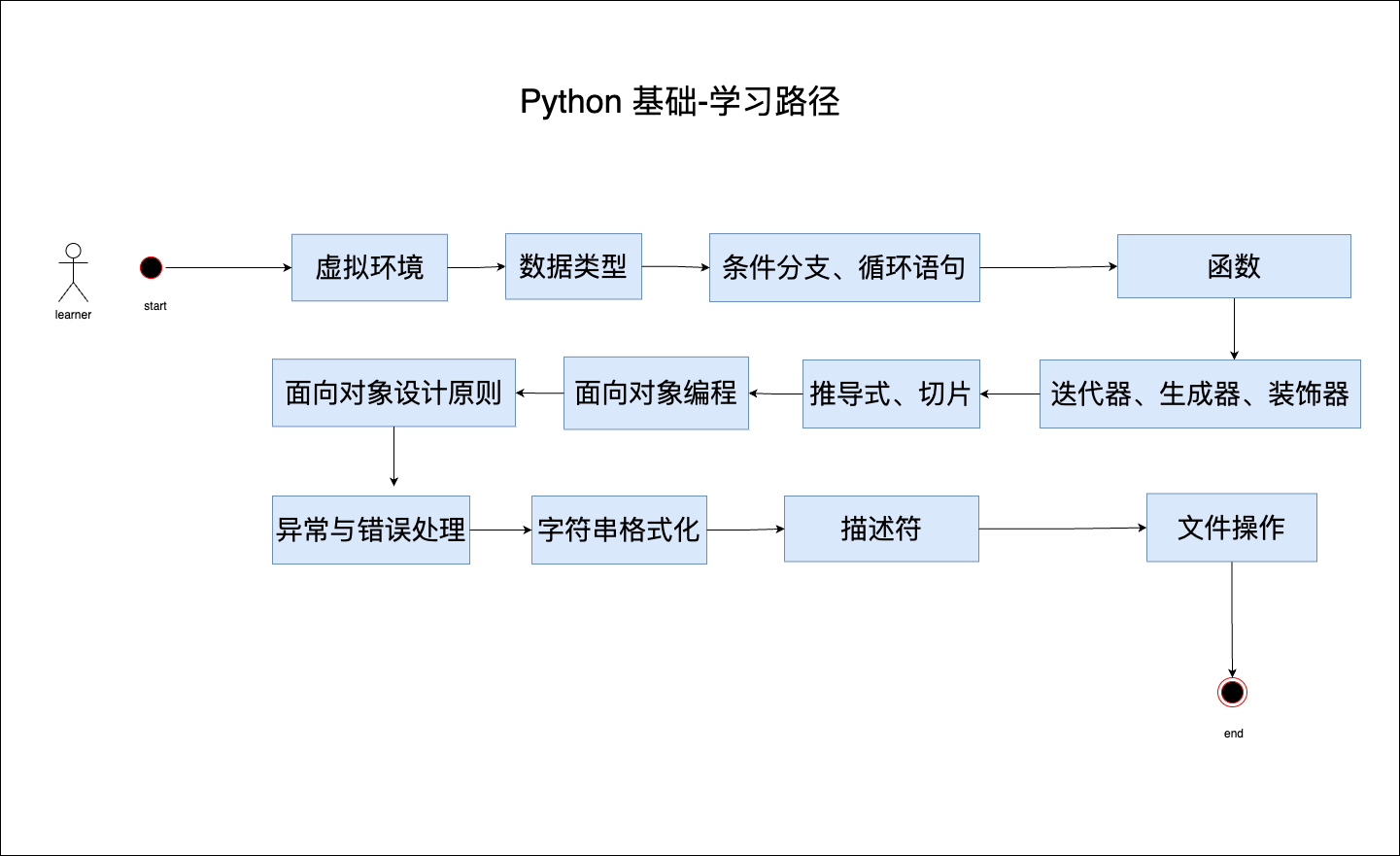
知识路径
虚拟环境
大家都知道,运行程序文件python app.py,使用的默认全局虚拟环境。在项目工程中,不可避免的工程代码文件、依赖第三方包的增多,不便于维护及多人协作,同时多个项目依赖非常容易相互冲突影响,由此可看虚拟环境的重要。
常见环境、包管理命令如下:
Python的venv模块
- 创建tutorial-env环境
python -m venv tutorial-env python -m venv tutorial-env- 激活tutorial-env环境
// windows
tutorial-env\Scripts\activate.bat
//Unix或MacOS
source tutorial-env/bin/activate // windows
tutorial-env\Scripts\activate.bat
//Unix或MacOS
source tutorial-env/bin/activate- 退出环境
deactivate
pip包管理命令
// 安装包
python -m pip install novas
// 安装包并指定版本
pip install requests==2.6.0
// 升级包
pip install --upgrade
// 卸载包
pip uninstall
// 显示虚拟环境中安装的所有软件包
pip list
// 显示有关特定包的信息
pip show
//生成一个类似的已安装包列表
pip freeze > requirements.txt
pip install -r requirements.txt
// 指定源进行安装包
pip install sqlalchemy -i https://mirrors.aliyun.com/pypi/simple/ // 安装包
python -m pip install novas
// 安装包并指定版本
pip install requests==2.6.0
// 升级包
pip install --upgrade
// 卸载包
pip uninstall
// 显示虚拟环境中安装的所有软件包
pip list
// 显示有关特定包的信息
pip show
//生成一个类似的已安装包列表
pip freeze > requirements.txt
pip install -r requirements.txt
// 指定源进行安装包
pip install sqlalchemy -i https://mirrors.aliyun.com/pypi/simple/Conda包管理器
环境相关
// 创建名为env_name的新环境,并在该环境下安装名为package_name 的包,可以指定新环境的版本号
// conda create -n env_name package_name
conda create -n python2 python=python2.7 numpy pandas
// 复制old_env_name为new_env_name创建新环境
// conda create --name new_env_name --clone old_env_name
// 创建名为ENVIRONMENT的虚拟环境
conda create -n ENVIRONMENT
//通过environment.yml文件创建环境
conda env create -f environment.yml
// 导出yml文件
conda env export > environment.yml
// 切换至env_name环境
conda activate env_name
// 退出的环境
conda deactivate
// 显示所有已经创建的环境
conda info -e
conda env list
// 删除环境
conda remove --name env_name –all
// 删除环境
conda env remove -n env_name
//查看镜像源
conda config --show channels
// 设置镜像源
conda config --add channels http://mirrors.aliyun.com/pypi/simple/
conda config --set show_channel_urls yes // 创建名为env_name的新环境,并在该环境下安装名为package_name 的包,可以指定新环境的版本号
// conda create -n env_name package_name
conda create -n python2 python=python2.7 numpy pandas
// 复制old_env_name为new_env_name创建新环境
// conda create --name new_env_name --clone old_env_name
// 创建名为ENVIRONMENT的虚拟环境
conda create -n ENVIRONMENT
//通过environment.yml文件创建环境
conda env create -f environment.yml
// 导出yml文件
conda env export > environment.yml
// 切换至env_name环境
conda activate env_name
// 退出的环境
conda deactivate
// 显示所有已经创建的环境
conda info -e
conda env list
// 删除环境
conda remove --name env_name –all
// 删除环境
conda env remove -n env_name
//查看镜像源
conda config --show channels
// 设置镜像源
conda config --add channels http://mirrors.aliyun.com/pypi/simple/
conda config --set show_channel_urls yes包操作
// 查看所有已经安装的包
conda list
// 在当前环境中安装包
conda install package_name
// 在指定环境中安装包
conda install --name env_name package_name
// 更新指定的包
conda update package_name
// 更新所有包
conda update --all
// 删除当前环境中的包
conda remove package
// 删除指定环境中的包
conda remove --name env_name package // 查看所有已经安装的包
conda list
// 在当前环境中安装包
conda install package_name
// 在指定环境中安装包
conda install --name env_name package_name
// 更新指定的包
conda update package_name
// 更新所有包
conda update --all
// 删除当前环境中的包
conda remove package
// 删除指定环境中的包
conda remove --name env_name package数据类型
python数据类型如下,一般划分为基本数据类型,与数据容器类型。 详细操作,查看官方文档
基本数据类型:
- 整数(int)
x = 5 - 浮点数(float)
y = 3.14 - 字符串(str)
name = "Alice" - 布尔值 (bool)
is_valid = False
容器类型:
- 列表(list)
numbers = [1, 2, 3, 4] - 元组(tuple)
point = (3, 4) - 字典(dictionary)
person = {"name": "Alice", "age": 25} - Set(集合)
my_set = {1, 2, 3} - range(数字序列)
range(10)
我们知道声明类型,通过字面量与构造函数,生成对应的类型。每个类型的属性与方法,我们可以通过构造函数的属性和方法,进行学习类型的功能,另外内置函数也可以同时对类型或者多个类型的进行操作。
接下来,对常用的容器类型的属性、操作方法进行梳理,其中python同时也内置函数对类型进行操作,🔗内置函数
set类型
1.创建Set:
1. my_set = {}(这将创建一个空字典,而不是集合)。
2. my_set = set()。
2.创建带有元素的Set:
* my_set = {1, 2, 3}
* my_set = set([1, 2, 3])
使用 set() 函数并传递一个可迭代对象(如列表、元组等)来创建具有初始元素的集合
3.添加元素到Set:
* my_set.add(4)
4.移除元素从Set:
* my_set.remove(3)
5.Set的基本操作:
* 使用 len() 函数获取集合中元素的数量:length = len(my_set)。
* 使用 in 关键字来检查元素是否存在于集合中:if 3 in my_set:。
* 使用 for 循环遍历集合中的元素。
6.Set的数学运算:
* 交集:使用 intersection() 方法或 & 运算符:
intersection_set = set1.intersection(set2) 或 intersection_set = set1 & set2。
* 并集:使用 union() 方法或 | 运算符:
union_set = set1.union(set2) 或 union_set = set1 | set2。
* 差集:使用 difference() 方法或 - 运算符:
difference_set = set1.difference(set2) 或 difference_set = set1 - set2。
* 对称差集:使用 symmetric_difference() 方法或 ^ 运算符:
sym_diff_set = set1.symmetric_difference(set2) 或 sym_diff_set = set1 ^ set2。
my_set = {1, 2, 3, 5, 3}
print(my_set)
my_set_01 = set((1,2,3, 2))
my_set_01.add(10)
my_set_01.remove(3)
isExist = 2 in my_set_01
for i in my_set_01:
print(f"遍历打印: {i}")
print(my_set_01, isExist, len(my_set_01))
set01 = { 1, 2, 3, 4, 2}
set02 = set((1, 2, 3, 4, 1, 2, 12, 2, 12, 1))
print(
f"set01 与 set02 的交集为{set01 & set02}",
f"\nset01 与 set02 的并集为{set01 | set02}",
f"\nset01 与 set02 的差集为{set02 - set01}",
"\nSt是否不在集合中, {}".format('st' not in my_set_01),
"\n两者是否没有交集, {}".format(my_set.isdisjoint(set01))
)my_set = {1, 2, 3, 5, 3}
print(my_set)
my_set_01 = set((1,2,3, 2))
my_set_01.add(10)
my_set_01.remove(3)
isExist = 2 in my_set_01
for i in my_set_01:
print(f"遍历打印: {i}")
print(my_set_01, isExist, len(my_set_01))
set01 = { 1, 2, 3, 4, 2}
set02 = set((1, 2, 3, 4, 1, 2, 12, 2, 12, 1))
print(
f"set01 与 set02 的交集为{set01 & set02}",
f"\nset01 与 set02 的并集为{set01 | set02}",
f"\nset01 与 set02 的差集为{set02 - set01}",
"\nSt是否不在集合中, {}".format('st' not in my_set_01),
"\n两者是否没有交集, {}".format(my_set.isdisjoint(set01))
){1, 2, 3, 5}
遍历打印: 10
遍历打印: 1
遍历打印: 2
{10, 1, 2} True 3
set01 与 set02 的交集为{1, 2, 3, 4}
set01 与 set02 的并集为{1, 2, 3, 4, 12}
set01 与 set02 的差集为{12}
St是否不在集合中, True
两者是否没有交集, False{1, 2, 3, 5}
遍历打印: 10
遍历打印: 1
遍历打印: 2
{10, 1, 2} True 3
set01 与 set02 的交集为{1, 2, 3, 4}
set01 与 set02 的并集为{1, 2, 3, 4, 12}
set01 与 set02 的差集为{12}
St是否不在集合中, True
两者是否没有交集, Falsedict 字典
创建方式:
- 花括号内以逗号分隔 键: 值对的方式
{4098: 'jack', 'name': 'sjoerd'} - 使用字典推导式: {}
{x: x ** 2 for x in range(10)} - 使用类型构造器: dict(),
dict([('foo', 100), ('bar', 200)]), dict(foo=100, bar=200)
由 dict.keys(), dict.values() 和 dict.items() 所返回的对象是 视图对象。
a = dict(one=1, two=2, three=3)
a['two'] = 12
del a['three']
for key in iter(a):
print(key)
val = a.get('three')
print(
'\n{0}'.format(len(a)),
list(a),
a['one'],
a['two'],
'two' in a,
'three' not in a,
iter(a)
)a = dict(one=1, two=2, three=3)
a['two'] = 12
del a['three']
for key in iter(a):
print(key)
val = a.get('three')
print(
'\n{0}'.format(len(a)),
list(a),
a['one'],
a['two'],
'two' in a,
'three' not in a,
iter(a)
)one
two
2 ['one', 'two'] 1 12 True True <dict_keyiterator object at 0x106c6fba0>one
two
2 ['one', 'two'] 1 12 True True <dict_keyiterator object at 0x106c6fba0>条件分支与循环
根据控制代码流向和执行。if,elif,else,break,coninue,pass
示例:
def getPerson(age:int) -> None:
if age < 6:
print(f'年龄为{age},未上学的小孩子')
elif age >= 10 and age < 18:
print(f'年龄为{age},上了学的小孩子')
else:
print(f'年龄为{age}的成年人了')
names = ['Michael', 'Bob', 'Tracy']
for name in names:
print(name)
def getBigNumber(num: int) -> int:
while num > 0:
num = num - 1
print(num)
return num
getPerson(3)
getPerson(11)
getPerson(19)
getPerson(29)
getBigNumber(3)def getPerson(age:int) -> None:
if age < 6:
print(f'年龄为{age},未上学的小孩子')
elif age >= 10 and age < 18:
print(f'年龄为{age},上了学的小孩子')
else:
print(f'年龄为{age}的成年人了')
names = ['Michael', 'Bob', 'Tracy']
for name in names:
print(name)
def getBigNumber(num: int) -> int:
while num > 0:
num = num - 1
print(num)
return num
getPerson(3)
getPerson(11)
getPerson(19)
getPerson(29)
getBigNumber(3)Michael
Bob
Tracy
年龄为3,未上学的小孩子
年龄为11,上了学的小孩子
年龄为19的成年人了
年龄为29的成年人了
2
1
0Michael
Bob
Tracy
年龄为3,未上学的小孩子
年龄为11,上了学的小孩子
年龄为19的成年人了
年龄为29的成年人了
2
1
0pass语句不执行任何动作continue终止本次循环,继续下一次循环操作break终止循环
函数的使用
函数基础
- 语言内置函数
- 定义函数
- 函数参数
- 递归函数
定义函数伪代码
def function_name(parameter1, parameter2, ...):
# 函数体代码
# 可选:使用 return 语句返回结果(如果需要)def function_name(parameter1, parameter2, ...):
# 函数体代码
# 可选:使用 return 语句返回结果(如果需要)常见语言内置函数
- print():用于打印输出文本或变量的值
- len():用于返回对象的长度或元素的个数。
- input():用于从用户获取输入,并以字符串的形式返回用户输入的值
- int():用于将一个对象转换为整数类型
- str():用于将一个对象转换为字符串类型。
- type():用于返回对象的类型
- range():用于生成一个指定范围的整数序列。
- sum():用于计算可迭代对象的总和。
float()\int()\str()\bool()\dict()\tuple()\set()
函数参数
- 默认参数
- 基于元组的可变参数(*可变参数)
- 基于字典的可变参数(**可变参数)
递归函数
一个函数在内部调用自身本身,这个函数就是递归函数。
# 默认值
def power(x, n=2):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
# 元组的可变参数
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
# 字典的可变参数
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
# 递归函数
def fact(n):
if n==1:
return 1
return n * fact(n - 1)
print(
power(2),
calc(1, 2, 3, 4, 1, 2),
person('yi', 28, last='yi', first='yang')
)# 默认值
def power(x, n=2):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
# 元组的可变参数
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
# 字典的可变参数
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
# 递归函数
def fact(n):
if n==1:
return 1
return n * fact(n - 1)
print(
power(2),
calc(1, 2, 3, 4, 1, 2),
person('yi', 28, last='yi', first='yang')
)name: yi age: 28 other: {'last': 'yi', 'first': 'yang'}
4 35 Nonename: yi age: 28 other: {'last': 'yi', 'first': 'yang'}
4 35 None函数进阶
- 高阶函数
- 匿名函数(Lambda函数)
- 装饰器
- 偏函数
高阶函数 函数返回值是一个函数;或者一个函数作为一个函数的参数。
常见使用:
- map/reduce
- filter
- sorted
lambda函数
lambda arguments: expressionlambda arguments: expression装饰器
装饰器是Python中用于修改或增强函数或类的行为的一种特殊语法。装饰器使用了Python中的函数闭包和元编程的概念
偏函数
偏函数(Partial Function)是在函数式编程中常用的概念,它是通过固定函数的部分参数来创建一个新函数的技术。偏函数允许我们通过提供一部分参数值来创建一个新的函数,而不需要重复编写相同的参数值。
# 使用匿名函数求两个数的和
sum = lambda x, y: x + y
result = sum(3, 5)
print(result) # 输出: 8
# 使用map函数将列表中的每个元素平方
numbers = [1, 2, 3, 4, 5]
squared_numbers = map(lambda x: x**2, numbers)
print(list(squared_numbers)) # 输出: [1, 4, 9, 16, 25]
# 使用reduce函数计算列表中所有元素的累积和
from functools import reduce
numbers = [1, 2, 3, 4, 5]
sum = reduce(lambda x, y: x + y, numbers)
print(sum) # 输出: 15
# 使用sorted函数对字符串列表按照长度进行排序
fruits = ['apple', 'banana', 'cherry', 'dragon fruit']
sorted_fruits = sorted(fruits, key=lambda x: len(x))
print(sorted_fruits) # 输出: ['apple', 'cherry', 'banana', 'dragon fruit']
# 装饰器
def decorator_function(func):
def wrapper():
print("Before function execution")
func()
print("After function execution")
return wrapper
@decorator_function
def hello():
print("Hello, world!")
hello()
#偏函数
from functools import partial
# 定义一个函数
def power(base, exponent):
return base ** exponent
# 创建一个偏函数,固定base参数为2
power_of_2 = partial(power, base=2)
# 调用偏函数
result = power_of_2(exponent=3)
print(result) # 输出: 8# 使用匿名函数求两个数的和
sum = lambda x, y: x + y
result = sum(3, 5)
print(result) # 输出: 8
# 使用map函数将列表中的每个元素平方
numbers = [1, 2, 3, 4, 5]
squared_numbers = map(lambda x: x**2, numbers)
print(list(squared_numbers)) # 输出: [1, 4, 9, 16, 25]
# 使用reduce函数计算列表中所有元素的累积和
from functools import reduce
numbers = [1, 2, 3, 4, 5]
sum = reduce(lambda x, y: x + y, numbers)
print(sum) # 输出: 15
# 使用sorted函数对字符串列表按照长度进行排序
fruits = ['apple', 'banana', 'cherry', 'dragon fruit']
sorted_fruits = sorted(fruits, key=lambda x: len(x))
print(sorted_fruits) # 输出: ['apple', 'cherry', 'banana', 'dragon fruit']
# 装饰器
def decorator_function(func):
def wrapper():
print("Before function execution")
func()
print("After function execution")
return wrapper
@decorator_function
def hello():
print("Hello, world!")
hello()
#偏函数
from functools import partial
# 定义一个函数
def power(base, exponent):
return base ** exponent
# 创建一个偏函数,固定base参数为2
power_of_2 = partial(power, base=2)
# 调用偏函数
result = power_of_2(exponent=3)
print(result) # 输出: 88
[1, 4, 9, 16, 25]
15
['apple', 'banana', 'cherry', 'dragon fruit']
Before function execution
Hello, world!
After function execution
88
[1, 4, 9, 16, 25]
15
['apple', 'banana', 'cherry', 'dragon fruit']
Before function execution
Hello, world!
After function execution
8迭代器、生成器、装饰器
生成器与迭代器
迭代器(iterator)和生成器(generator)是用于处理和生成可迭代对象的重要概念。装饰器见上一节
- 生成器(Generator):生成器是一种特殊的迭代器,它可以通过使用
yield关键字在函数内部逐个生成值。生成器函数在每次迭代时产生一个值,而不是将所有值一次性生成。 - 迭代器是一种对象,它通过实现__iter__()和__next__()方法来提供迭代功能。迭代器可以逐个返回元素,直到没有元素可供迭代。
可以使用isinstance()判断一个对象是否是Iterable对象: for循环的数据类型有以下几种:
- 一类是集合数据类型,如list、tuple、dict、set、str等;
- 一类是generator,包括生成器和带yield的generator function。
from collections.abc import Iterable
# 判断是否是迭代器
print(isinstance([], Iterable))
# 生成器
def my_generator():
yield 1
yield 2
# 生成器函数
gen = my_generator()
print(next(gen)) # 输出: 1
print(next(gen)) # 输出: 2
g = (x * x for x in range(10))
for n in g:
print(n)
# 可以使用iter()函数从可迭代对象中创建一个迭代器。
my_list = [1, 2, 3, 4, 5]
my_iter = iter(my_list)
print(next(my_iter)) # 输出: 1
print(next(my_iter)) # 输出: 2from collections.abc import Iterable
# 判断是否是迭代器
print(isinstance([], Iterable))
# 生成器
def my_generator():
yield 1
yield 2
# 生成器函数
gen = my_generator()
print(next(gen)) # 输出: 1
print(next(gen)) # 输出: 2
g = (x * x for x in range(10))
for n in g:
print(n)
# 可以使用iter()函数从可迭代对象中创建一个迭代器。
my_list = [1, 2, 3, 4, 5]
my_iter = iter(my_list)
print(next(my_iter)) # 输出: 1
print(next(my_iter)) # 输出: 2True
1
2
0
1
4
9
16
25
36
49
64
81
1
2True
1
2
0
1
4
9
16
25
36
49
64
81
1
2推导式、切片
推导式的使用
推导式(Comprehension)是一种简洁的语法,用于从可迭代对象创建新的数据结构(如列表、字典、集合)或进行筛选和转换操作。
- 列表推导式
- 字典推导式
- 集合推导式
伪代码:
new_list = [expression for item in iterable if condition]
new_dict = {key_expression: value_expression for item in iterable if condition}
new_set = {expression for item in iterable if condition}new_list = [expression for item in iterable if condition]
new_dict = {key_expression: value_expression for item in iterable if condition}
new_set = {expression for item in iterable if condition}# 列表推导式
numbers = [1, 2, 3, 4, 5]
tuples = (1, 2, 1)
squared_numbers = [x*2 for x in numbers if x % 2 == 0]
squared_tuples = [x**y for x in tuples if x % 2 == 0 for y in numbers if y % 2 == 0] #多重遍历
num = list(range(1, 11, 2)) # 序列
d = {'x': 'A', 'y': 'B', 'z': 'C' }
print(squared_numbers, squared_tuples, num, [k + '=' + v for k, v in d.items()])# 列表推导式
numbers = [1, 2, 3, 4, 5]
tuples = (1, 2, 1)
squared_numbers = [x*2 for x in numbers if x % 2 == 0]
squared_tuples = [x**y for x in tuples if x % 2 == 0 for y in numbers if y % 2 == 0] #多重遍历
num = list(range(1, 11, 2)) # 序列
d = {'x': 'A', 'y': 'B', 'z': 'C' }
print(squared_numbers, squared_tuples, num, [k + '=' + v for k, v in d.items()])[4, 8] [4, 16] [1, 3, 5, 7, 9] ['x=A', 'y=B', 'z=C'][4, 8] [4, 16] [1, 3, 5, 7, 9] ['x=A', 'y=B', 'z=C']#字典推导
numbers = [1, 2, 3, 4, 5]
squared_dict = {x: x**2 for x in numbers if x % 2 == 0}
# 结果为 {2: 4, 4: 16}
print(squared_dict)#字典推导
numbers = [1, 2, 3, 4, 5]
squared_dict = {x: x**2 for x in numbers if x % 2 == 0}
# 结果为 {2: 4, 4: 16}
print(squared_dict)# 集合推导
numbers = [1, 2, 3, 4, 5]
squared_set = {x**2 for x in numbers if x % 2 == 0}
# 结果为 {4, 16}
print(squared_set) # {16, 4}# 集合推导
numbers = [1, 2, 3, 4, 5]
squared_set = {x**2 for x in numbers if x % 2 == 0}
# 结果为 {4, 16}
print(squared_set) # {16, 4}num = list(x*y for x in range(2) for y in range(x, x + 10))
print(num, '\n{0}'.format(len(num)))num = list(x*y for x in range(2) for y in range(x, x + 10))
print(num, '\n{0}'.format(len(num)))[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
20[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
20切片
切片(slicing)是一种通过指定起始索引、结束索引和步长来访问序列对象(如字符串、列表、元组)的子序列的方法。 语法
sequence[start:stop:step]sequence[start:stop:step]其中:
- start:起始索引,表示切片的起始位置(包含在切片内)。
- stop:结束索引,表示切片的结束位置(不包含在切片内)。
- step:步长,表示切片的间隔,默认为1。
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 提取部分序列
subset1 = numbers[2:6] # 获取索引 2 到 5 的元素,结果为 [3, 4, 5, 6]
subset2 = numbers[:5] # 获取索引 0 到 4 的元素,结果为 [1, 2, 3, 4, 5]
subset3 = numbers[7:] # 获取索引 7 到末尾的元素,结果为 [8, 9, 10]
# 使用步长
subset4 = numbers[1:8:2] # 从索引 1 开始,每隔 2 个取一个元素,结果为 [2, 4, 6, 8]
# 反向切片
subset5 = numbers[::-1] # 反向切片,获取逆序的元素,结果为 [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
subset6 = numbers[::-3] # 反向切片,获取逆序的元素,结果为 [10, 7, 4, 1]
print(subset1, subset2, subset3, subset4, subset5, subset6)numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 提取部分序列
subset1 = numbers[2:6] # 获取索引 2 到 5 的元素,结果为 [3, 4, 5, 6]
subset2 = numbers[:5] # 获取索引 0 到 4 的元素,结果为 [1, 2, 3, 4, 5]
subset3 = numbers[7:] # 获取索引 7 到末尾的元素,结果为 [8, 9, 10]
# 使用步长
subset4 = numbers[1:8:2] # 从索引 1 开始,每隔 2 个取一个元素,结果为 [2, 4, 6, 8]
# 反向切片
subset5 = numbers[::-1] # 反向切片,获取逆序的元素,结果为 [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
subset6 = numbers[::-3] # 反向切片,获取逆序的元素,结果为 [10, 7, 4, 1]
print(subset1, subset2, subset3, subset4, subset5, subset6)[3, 4, 5, 6] [1, 2, 3, 4, 5] [8, 9, 10] [2, 4, 6, 8] [10, 9, 8, 7, 6, 5, 4, 3, 2, 1] [10, 7, 4, 1][3, 4, 5, 6] [1, 2, 3, 4, 5] [8, 9, 10] [2, 4, 6, 8] [10, 9, 8, 7, 6, 5, 4, 3, 2, 1] [10, 7, 4, 1]面向对象编程
面向对象编程,简称OOP,是一种程序设计思想。OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
特性:
- 封装
- 多态
- 继承
SOLID原则
- 单一职责
- 开放-关闭原则
- 里式替换原则
- 接口隔离原则
- 依赖倒置原则
常见类的操作
- 装饰器
- 定制类的行为
装饰器
- @classmethod:将方法定义为类方法,使其成为与类相关并可以访问类的属性和调用类的方法的函数。
- @staticmethod:将方法定义为静态方法,使其成为与类相关但无需访问类实例的函数。
- @property:将方法转换为属性,可以通过访问属性的方式调用该方法。它提供了对属性的简洁访问和控制。
- 定制类装饰器、方法装饰器、参数装饰器
类内置钩子
- init:初始化方法,用于在对象创建时进行初始化操作。
- str:字符串表示方法,用于返回对象的字符串表示。
- len:长度方法,用于返回对象的长度。
- getitem:索引访问方法,用于实现通过索引访问对象的元素。
- call:可调用方法,用于使对象本身可调用,就像函数一样调用。
- repr:用于返回对象的可打印表示,通常用于调试目的
- iter 和 next:用于实现可迭代对象和迭代器的协议。
- enter 和 exit:用于实现上下文管理器协议,控制对象的进入和离开上下文时的操作。
- eq 和 ne:用于定义对象的相等性和不等性。
# 类方法
class MyClass:
class_variable = "Hello, class!"
@classmethod
def class_method(cls):
print("Class variable:", cls.class_variable)
MyClass.class_method()
# 静态方法
class MathUtils:
@staticmethod
def add(x, y):
return x + y
result = MathUtils.add(3, 5)
#存取器
class Person:
def __init__(self, name):
self._name = name
@property
def name(self):
return self._name
person = Person("Alice")
print(person.name) # 直接访问属性,而不是调用方法
# 类装饰器
def class_decorator(cls):
# 可以在这里修改原始类或创建新的类
modified_class = cls
# 返回修改后的类
return modified_class
@class_decorator
class MyClass:
pass
def method_decorator(func):
def modified_method(self, *args, **kwargs):
# 可以在这里修改原始方法的行为
result = func(self, *args, **kwargs)
# 或者定义新的方法
return result
# 返回修改后的方法
return modified_method
class MyClass:
@method_decorator
def my_method(self):
pass# 类方法
class MyClass:
class_variable = "Hello, class!"
@classmethod
def class_method(cls):
print("Class variable:", cls.class_variable)
MyClass.class_method()
# 静态方法
class MathUtils:
@staticmethod
def add(x, y):
return x + y
result = MathUtils.add(3, 5)
#存取器
class Person:
def __init__(self, name):
self._name = name
@property
def name(self):
return self._name
person = Person("Alice")
print(person.name) # 直接访问属性,而不是调用方法
# 类装饰器
def class_decorator(cls):
# 可以在这里修改原始类或创建新的类
modified_class = cls
# 返回修改后的类
return modified_class
@class_decorator
class MyClass:
pass
def method_decorator(func):
def modified_method(self, *args, **kwargs):
# 可以在这里修改原始方法的行为
result = func(self, *args, **kwargs)
# 或者定义新的方法
return result
# 返回修改后的方法
return modified_method
class MyClass:
@method_decorator
def my_method(self):
pass面向对象设计原则
SOLID原则
- 单一职责
- 开放-关闭原则
- 里式替换原则
- 接口隔离原则
- 依赖倒置原则
TODO
异常与错误处理
所有内置的非系统退出类异常都派生自此类Exception,常见具体异常如下:
- AssertionError 当 assert 语句失败时将被引发
- EOFError 当 input() 函数未读取任何数据即达到文件结束条件 (EOF) 时将被引发。
- ImportError 当 import 语句尝试加载模块遇到麻烦时将被引发
- IndexError 当序列抽取超出范围时将被引发
- OSError 此异常在一个系统函数返回系统相关的错误时将被引发
- RuntimeError 当检测到一个不归属于任何其他类别的错误时将被引发
- SyntaxError 当解析器遇到语法错误时引发
查看其他异常类型
1.语法错误
while True print('Hello world')
File "<stdin>", line 1
while True print('Hello world')
^
SyntaxError: invalid syntaxwhile True print('Hello world')
File "<stdin>", line 1
while True print('Hello world')
^
SyntaxError: invalid syntax2.异常
表达式使用了正确的语法,执行时仍可能触发错误.
10 * (1/0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero10 * (1/0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero3.异常的处理
while True:
try:
x = int(input("Please enter a number: "))
break
except ValueError:
print("Oops! That was no valid number. Try again...")while True:
try:
x = int(input("Please enter a number: "))
break
except ValueError:
print("Oops! That was no valid number. Try again...")except 子句 可以用带圆括号的元组来指定多个异常
except (RuntimeError, TypeError, NameError):
passexcept (RuntimeError, TypeError, NameError):
pass4.触发异常
raise 语句支持强制触发指定的异常
raise NameError('HiThere')raise NameError('HiThere')5.异常链
try 语句可以有多个 except 子句 来为不同的异常指定处理程序。 但最多只有一个处理程序会被执行
import sys
try:
f = open('myfile.txt')
s = f.readline()
i = int(s.strip())
except OSError as err:
print("OS error: {0}".format(err))
except ValueError:
print("Could not convert data to an integer.")
except BaseException as err:
print(f"Unexpected {err=}, {type(err)=}")
raiseimport sys
try:
f = open('myfile.txt')
s = f.readline()
i = int(s.strip())
except OSError as err:
print("OS error: {0}".format(err))
except ValueError:
print("Could not convert data to an integer.")
except BaseException as err:
print(f"Unexpected {err=}, {type(err)=}")
raise6.定义清理操作
try:
raise KeyboardInterrupt
finally:
print('Goodbye, world!')try:
raise KeyboardInterrupt
finally:
print('Goodbye, world!')def divide(x, y):
try:
result = x / y
except ZeroDivisionError:
print("division by zero!")
else:
print("result is", result)
finally:
print("executing finally clause")
divide(3, 1)
divide(2, 0)
divide("2", "1")def divide(x, y):
try:
result = x / y
except ZeroDivisionError:
print("division by zero!")
else:
print("result is", result)
finally:
print("executing finally clause")
divide(3, 1)
divide(2, 0)
divide("2", "1")result is 3.0
executing finally clause
division by zero!
executing finally clause
executing finally clause
TypeError Traceback (most recent call last)
/Users/yangyi/Documents/try code/demo-py/py-basic.ipynb 单元格 44 line 1
11 divide(3, 1)
14 divide(2, 0)
---> 17 divide("2", "1")
/Users/yangyi/Documents/try code/demo-py/py-basic.ipynb 单元格 44 line 3
1 def divide(x, y):
2 try:
----> 3 result = x / y
4 except ZeroDivisionError:
5 print("division by zero!")
TypeError: unsupported operand type(s) for /: 'str' and 'str'result is 3.0
executing finally clause
division by zero!
executing finally clause
executing finally clause
TypeError Traceback (most recent call last)
/Users/yangyi/Documents/try code/demo-py/py-basic.ipynb 单元格 44 line 1
11 divide(3, 1)
14 divide(2, 0)
---> 17 divide("2", "1")
/Users/yangyi/Documents/try code/demo-py/py-basic.ipynb 单元格 44 line 3
1 def divide(x, y):
2 try:
----> 3 result = x / y
4 except ZeroDivisionError:
5 print("division by zero!")
TypeError: unsupported operand type(s) for /: 'str' and 'str'字符串格式化
详情查看:字符串格式化文档
常见操作如下:
# 按位置访问参数:
print('{2}, {1}, {0}'.format(*'abc'))
# 按名称访问参数:
print('Coordinates: {latitude}, {longitude}'.format(latitude='37.24N', longitude='-115.81W'))
# 访问参数的属性
class Point:
def __init__(self, x, y):
self.x, self.y = x, y
def __str__(self):
return 'Point({self.x}, {self.y})'.format(self=self)
print(str(Point(4,2)))
# 访问参数的项:
coord = (3, 5)
print('X: {0[0]}; Y: {0[1]}'.format(coord))
# 替代 %s 和 %r:
print("repr() shows quotes: {!r}; str() doesn't: {!s}".format('test1', 'test2'))
# 对齐文本以及指定宽度:
print('{:<30}l'.format('left aligned'))
print('{:*^30}'.format('centered')) # use '*' as a fill char
# 替代 %+f, %-f 和 % f 以及指定正负号:
print('{:+f}; {:+f}'.format(3.14, -3.14))
# 替代 %x 和 %o 以及转换基于不同进位制的值:
print("int: {0:d}; hex: {0:x}; oct: {0:o}; bin: {0:b}".format(42))
# 使用逗号作为千位分隔符:
print('{:,}'.format(1234567890))
# 表示为百分数:
print('Correct answers: {:.2%}'.format(19/23))
# 使用特定类型的专属格式化:
import datetime
d = datetime.datetime(2010, 7, 4, 12, 15, 58)
print('{:%Y-%m-%d %H:%M:%S}'.format(d))# 按位置访问参数:
print('{2}, {1}, {0}'.format(*'abc'))
# 按名称访问参数:
print('Coordinates: {latitude}, {longitude}'.format(latitude='37.24N', longitude='-115.81W'))
# 访问参数的属性
class Point:
def __init__(self, x, y):
self.x, self.y = x, y
def __str__(self):
return 'Point({self.x}, {self.y})'.format(self=self)
print(str(Point(4,2)))
# 访问参数的项:
coord = (3, 5)
print('X: {0[0]}; Y: {0[1]}'.format(coord))
# 替代 %s 和 %r:
print("repr() shows quotes: {!r}; str() doesn't: {!s}".format('test1', 'test2'))
# 对齐文本以及指定宽度:
print('{:<30}l'.format('left aligned'))
print('{:*^30}'.format('centered')) # use '*' as a fill char
# 替代 %+f, %-f 和 % f 以及指定正负号:
print('{:+f}; {:+f}'.format(3.14, -3.14))
# 替代 %x 和 %o 以及转换基于不同进位制的值:
print("int: {0:d}; hex: {0:x}; oct: {0:o}; bin: {0:b}".format(42))
# 使用逗号作为千位分隔符:
print('{:,}'.format(1234567890))
# 表示为百分数:
print('Correct answers: {:.2%}'.format(19/23))
# 使用特定类型的专属格式化:
import datetime
d = datetime.datetime(2010, 7, 4, 12, 15, 58)
print('{:%Y-%m-%d %H:%M:%S}'.format(d))c, b, a
Coordinates: 37.24N, -115.81W
Point(4, 2)
X: 3; Y: 5
repr() shows quotes: 'test1'; str() doesn't: test2
left aligned l
***********centered***********
+3.140000; -3.140000
int: 42; hex: 2a; oct: 52; bin: 101010
1,234,567,890
Correct answers: 82.61%
2010-07-04 12:15:58c, b, a
Coordinates: 37.24N, -115.81W
Point(4, 2)
X: 3; Y: 5
repr() shows quotes: 'test1'; str() doesn't: test2
left aligned l
***********centered***********
+3.140000; -3.140000
int: 42; hex: 2a; oct: 52; bin: 101010
1,234,567,890
Correct answers: 82.61%
2010-07-04 12:15:58描述符
在所有Python对象协议里,描述符可能是其中应用最广却又最鲜为人知的协议之一。 所有的方法、类方法、静态方法以及属性等诸多Python内置对象,都是基于描述符协议实现的。 文档
相关操作,对应的魔术方法如下:
obj[key]、__getitem++定义索引读取行为obj[key] = value、__setitem++定义按索引写入行为del obj[key]、__delitem++定义索引删除行为len(obj)、__len__定义对象的长度行为bool(obj)、__bool__定义对象的布尔值真假行为obj == another_obj、__eq__定义==运算时取行为with obj:、__enter__、__exit__定义对象作为上下文管理器行为for _ in obj、__iter__、__next__定义对象迭代时行为obj()、__call__定义被调用行为obj_class()、__new__定义创建实例行为
无描述符
class Person:
def __init__(self, name, age):
self.name = name
self.age = ageclass Person:
def __init__(self, name, age):
self.name = name
self.age = age有描述符
class Person:
...
@property
def age(self):
return self._age
@age.setter
def age(self, value):
"""设置年龄,只允许 0~150 之间的数值"""
try:
value = int(value)
except (TypeError, ValueError):
raise ValueError('value is not a valid integer!')
if not (0 < value < 150):
raise ValueError('value must between 0 and 150!')
self._age = valueclass Person:
...
@property
def age(self):
return self._age
@age.setter
def age(self, value):
"""设置年龄,只允许 0~150 之间的数值"""
try:
value = int(value)
except (TypeError, ValueError):
raise ValueError('value is not a valid integer!')
if not (0 < value < 150):
raise ValueError('value must between 0 and 150!')
self._age = valueclass IntegerField:
"""整型字段,只允许一定范围内的整型值
:param min_value: 允许的最小值
:param max_value: 允许的最大值
"""
def __init__(self, min_value, max_value):
self.min_value = min_value
self.max_value = max_value
def __get__(self, instance, owner=None):
# 当不是通过实例访问时,直接返回描述符对象
if not instance:
return self
# 返回保存在实例字典里的值
return instance.__dict__['_integer_field']
def __set__(self, instance, value):
# 校验后将值保存在实例字典里
value = self._validate_value(value)
instance.__dict__['_integer_field'] = value
def _validate_value(self, value):
"""校验值是否为符合要求的整数"""
try:
value = int(value)
except (TypeError, ValueError):
raise ValueError('value is not a valid integer!')
if not (self.min_value <= value <= self.max_value):
raise ValueError(
f'value must between {self.min_value} and {self.max_value}!'
)
return valueclass IntegerField:
"""整型字段,只允许一定范围内的整型值
:param min_value: 允许的最小值
:param max_value: 允许的最大值
"""
def __init__(self, min_value, max_value):
self.min_value = min_value
self.max_value = max_value
def __get__(self, instance, owner=None):
# 当不是通过实例访问时,直接返回描述符对象
if not instance:
return self
# 返回保存在实例字典里的值
return instance.__dict__['_integer_field']
def __set__(self, instance, value):
# 校验后将值保存在实例字典里
value = self._validate_value(value)
instance.__dict__['_integer_field'] = value
def _validate_value(self, value):
"""校验值是否为符合要求的整数"""
try:
value = int(value)
except (TypeError, ValueError):
raise ValueError('value is not a valid integer!')
if not (self.min_value <= value <= self.max_value):
raise ValueError(
f'value must between {self.min_value} and {self.max_value}!'
)
return value文件操作
open() 返回一个 file object ,最常使用的是两个位置参数和一个关键字参数:open(filename, mode, encoding=None)
详情查看:文档
mode模式有:
- 'r' 读取(默认)
- 'w' 写入,并先截断文件
- 'x' 排它性创建,如果文件已存在则失败
- 'a' 打开文件用于写入,如果文件存在则在末尾追加
- 'b' 二进制模式
- 't' 文本模式(默认)
- '+' 打开用于更新(读取与写入
with open('workfile', encoding="utf-8") as f:
read_data = f.read() with open('workfile', encoding="utf-8") as f:
read_data = f.read()文件对象的方法:
- f.read(size) 可用于读取文件内容,它会读取一些数据。
- f.readline(size) 从文件中读取单行数据;字符串末尾保留换行符(\n),只有在文件不以换行符结尾时,文件的最后一行才会省略换行符。
- f.readlines() 读取文件数据到一个字符串列表
- f.write(s) 写入字符串s到文件,返回字符串数
- f.writelines(lines) 向文件中写入一个字符串列表,不添加行分隔符。
- flush() 刷新缓冲区
with open('./open.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
copy_name = 'open_copy.txt'
with open(copy_name, 'w', encoding='utf-8') as ff:
ff.writelines(lines)with open('./open.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
copy_name = 'open_copy.txt'
with open(copy_name, 'w', encoding='utf-8') as ff:
ff.writelines(lines)